Connect ATP Private EndPoint Database via Public Load Balancer
In my previous post, we have seen How to create ATP Database with Private Endpoint aka with private dedicated IP of ATP database. Click here to refer previous post.
Now, in this post we will see how we can connect an ATP database (created with a private endpoint) via public load balancer.
Click on Networking -> Load balancer -> load balancer
Click on "Create load balancer" button

- Provide Load balancer name = CBTPubLB
- Choose visibility type = Public
- Assign a public IP address = Ephemeral IP Address (This will automatically assign a public IP address from the available IP address from the pool.)

- Choose VCN = cbtvcn (Your VCN)
- Choose subnet = public subnet-cbtvcn (Your public subnet)
Now Click Next.
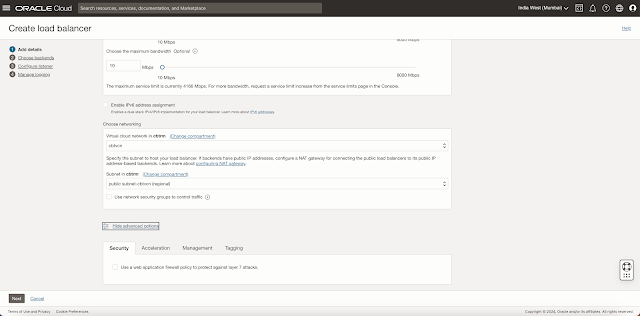
Note that in my case I will add backends after creating the Load balancer. If you want to add a backend now, you can.
Now, specify the health check policy
- Choose Protocol as TCP from the dropdown menu.
- Choose Port = 1522
Leave other fields as default

below screenshots are just for your references purpose.



Click Next to configure Listener
- Provide proper Listener name, In my case, it is "DB_LSNR"
- Specify the type of traffic as TCP
- Specify the port as 1522
I am not providing any SSL certificate here.

Now, You can enable the Error log and access log,
Here in my case I have enabled only Error log, please refer below screenshot

Click on Submit button to create load balancer
It will take a couple of minutes to create a load balancer.


Now you can see the load balancer is created but the health is Critical. This is due to backendset. Yet we have not configured the backend set.
Now Click on the Backend sets -> Backends -> Add backends
Provide the IP address of your ATP database which is shown under the Network section of your ATP detail page. Please refer to the screenshot below for your reference.

Here you can see number of backends are zeero.

Click on Add backends button

Provide IP address and port number.
Click Add button

Click on close button to close the window.

Once added, health will be in critical state, It will take a couple of minutes to change the health status.

You can see backend is added but health is in Critical state.

You can see more details by moving your mouse pointer on Critical text.

Must remember that, you need to configure VCN ingress rule for your private and public subnet.
In my example, refer below screenshot of default security list - public subnet and Private security list for private subnet.


Once done, check the status of your public load balancer.
Backend health must be OK. This means that the Load balancer is able to ping the ATP database.
Now you can see the backend health in Green Icon as OK.
After adding ingress rule it will take 1-2 minutes to reflect in load balancer to make the health OK.

You can see the overall load balancer health is now also in Green- OK

Now, Click on the Autonomous database CBTATP1 -> click on the "Database connection" button.
Click on Download wallet button -> provide the wallet password.

It will download the zip file. Unzip the wallet.zip file.
Open the tnsnames.ora file
Replace your ATP host name with the Public Load Balancer IP.
refer below screenshot for your reference.
Save tnsnames.ora file

Zip all the files again and give another name of zip file. Here in my case it is CBTATP_LB_IP.zip.
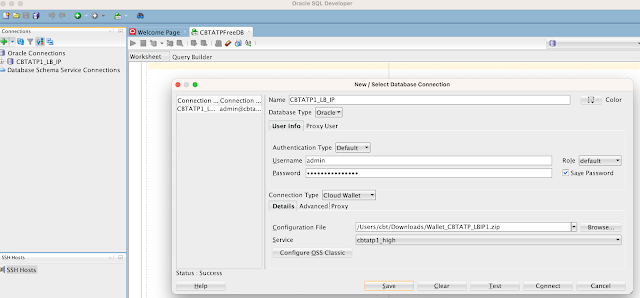
Open the SQL developer -> click on new connection
- Provide connection name - CBTATP1DB
- username = admin
- password = <admin password> (This is the same password which you given during creation of your ATP database)
- choose connection Type= Cloud Wallet
Browse and select the .zip file which you created just now.
click on the test button to test.
This is it.
Hope this article will help you.
Thanks for reading.
Thanks & Regards,
Chandan Tanwani























